Introducción
En el mundo del Cloud Engineering, abandonar la interfaz gráfica a favor de la automatización es un rito de iniciación. En este artículo, aprenderás a crear cuenta de almacenamiento Azure CLI, pasando de la teoría fundamental a la implementación práctica de infraestructura como código (IaC) directamente desde tu terminal. Resolveremos el problema clásico de desplegar un entorno de almacenamiento seguro, público para lectura de activos web, pero blindado contra modificaciones no autorizadas.
A diferencia de los discos tradicionales (Managed Disks) que se conectan a una sola máquina virtual, hoy utilizaremos Azure Blob Storage. Este servicio actúa como un gigantesco lago de datos accesible globalmente vía HTTP/HTTPS, ideal para servir páginas web estáticas, almacenar copias de seguridad masivas o centralizar logs.
A lo largo de este tutorial, exploraremos no solo los comandos necesarios, sino la arquitectura detrás de ellos: desde la gestión de identidades con Microsoft Entra ID hasta la separación estricta de planos de control y datos (Zero Trust). Prepárate para llevar tus habilidades de Azure al siguiente nivel.
Requisitos Previos
Para seguir este tutorial utilizando tu entorno de desarrollo local, necesitarás lo siguiente:
- Editor de Código: Tener instalado Visual Studio Code (VS Code).
- Herramienta de Línea de Comandos: Instalación de Azure CLI en tu sistema operativo (Ubuntu, Windows o macOS).
- Extensiones de VS Code: La extensión oficial “Azure CLI Tools” para tener resaltado de sintaxis y autocompletado.
- Cuenta Cloud: Una suscripción de Microsoft Azure activa (puedes usar la capa gratuita).
- Navegador Web: Un navegador actualizado para probar el resultado final.
Repositorio de GitHub
https://github.com/DavidGonzalezCloud/azure-cli-journey.git
Paso a Paso del Ejercicio
Teoría y Conceptos Fundamentales (El Paradigma de Objetos)
Antes de teclear código, es crucial entender qué estamos construiendo.
Almacenamiento en Bloque vs. Almacenamiento de Objetos
En las arquitecturas tradicionales, los discos (Managed Disks) actúan como hardware físico atado a un sistema de archivos (NTFS, ext4). En contraste, Azure Blob Storage es un almacenamiento de objetos. No hay carpetas físicas, todo es un espacio plano donde miles de clientes pueden leer información simultáneamente, lo que lo hace perfecto para la web.
Jerarquía Estructural
Tu arquitectura de datos se dividirá en tres fronteras lógicas:
- Storage Account: El contenedor maestro. Define la región, la redundancia física y la facturación.
- Container: El perímetro de seguridad interno. Agrupa los datos y aplica reglas de cortafuegos lógicos.
- Blob: El archivo en sí y sus metadatos.
La Estrategia FinOps (Access Tiers)
Azure permite clasificar la “temperatura” del dato para optimizar costos:
- Hot (Frecuente): Almacenamiento costoso, lectura barata (Ideal para webs).
- Cool (Esporádico): Almacenamiento barato, penalización por lectura (Ideal para reportes mensuales).
- Archive (Archivo): Almacenamiento ultra-barato, datos “congelados” (Ideal para retención legal de 7 años).
Seguridad Zero Trust y Defensa en Profundidad
Azure separa los permisos en el Management Plane (Plano de Control – crear/destruir infraestructura con ARM) y el Data Plane (Plano de Datos – leer/escribir archivos). Crear la cuenta no te da acceso a los datos por defecto; necesitamos inyectar roles (RBAC) explícitamente.
Despliegue Práctico: Crear cuenta de almacenamiento Azure CLI
Abre tu terminal en VS Code y asegúrate de haber iniciado sesión ejecutando az login. A continuación, ejecutaremos nuestro script secuencial.
Paso 1: Declaración de Entorno
Nunca debemos codificar valores “en duro” (hardcoding). Primero, preparamos las variables y extraemos nuestro ID de identidad de Microsoft Entra ID. ¿Por qué? Porque lo necesitaremos para inyectarnos permisos de seguridad más adelante.
# Variables del sistema (Asegúrate de que el grupo de recursos ya exista o créalo previamente)
RG_NAME="rg-portfolio-prod"
LOCATION="eastus"
STORAGE_NAME="stportfolio$RANDOM" # Usamos RANDOM para asegurar un nombre globalmente único
CONTAINER_NAME="web"
# Creacion Grupo de Recursos
az group create \
--name $RG_NAME \
--location eastus \
--tags environment=devPaso 2: Aprovisionamiento del Plano de Control
Ahora creamos la Storage Account. Para que nuestro contenedor web pueda ser visto desde internet al final del ejercicio, debemos encender un “interruptor maestro” de seguridad desde el nacimiento del recurso usando la bandera –allow-blob-public-access true
az storage account create \
--name $STORAGE_NAME \
--resource-group $RG_NAME \
--location $LOCATION \
--sku Standard_LRS \
--allow-blob-public-access true
Paso 3: Asignación de Roles (Atravesando al Plano de Datos)
Aquí aplicamos el principio Zero Trust. Asignamos el rol Storage Blob Data Contributor a nuestra propia cuenta para tener autoridad sobre los archivos internos. Agregamos un comando sleep porque los centros de datos globales de Azure tardan unos segundos en propagar el token criptográfico.
# Obtenemos el ID exacto del recurso recién creado
STORAGE_ID=$(az storage account show --name $STORAGE_NAME --resource-group $RG_NAME --query id -o tsv)
# Extracción de identidad del usuario que estamos usando para darle los permisos necesarios.
USER_ID=$(az ad signed-in-user show --query id -o tsv)
# Inyectamos el rol de seguridad
az role assignment create \
--role "Storage Blob Data Contributor" \
--assignee $USER_ID \
--scope $STORAGE_ID
echo "Propagando permisos RBAC en la nube..."
sleep 60
Paso 4: Creación del Contenedor y Perímetro Público
Creamos el contenedor (web) usando nuestra identidad validada por Entra ID (--auth-mode login). Luego, configuramos el acceso público a nivel “blob”. Esto permite que alguien con la URL exacta descargue el archivo, pero prohíbe listar el contenido completo del contenedor por seguridad.
# Creación del perímetro lógico interno
az storage container create \
--name $CONTAINER_NAME \
--account-name $STORAGE_NAME \
--auth-mode login
# Apertura de lectura anónima a nivel objeto (usando auth-mode key por limitaciones heredadas de CLI)
az storage container set-permission \
--name $CONTAINER_NAME \
--account-name $STORAGE_NAME \
--public-access blob \
--auth-mode key
Paso 5: Inyección de Datos y Consumo
Finalmente, creamos nuestro sitio web estático localmente, lo inyectamos en nuestro lago de datos recién configurado y extraemos la URL pública para comprobar nuestro éxito.
# Generación del activo local
echo "<h1>Hola desde la nube de Azure</h1>" > index.html
# Carga al lago de datos usando autenticación moderna
az storage blob upload \
--account-name $STORAGE_NAME \
--container-name $CONTAINER_NAME \
--name "index.html" \
--file "index.html" \
--auth-mode login
# Auditoría y extracción del punto de enlace (Endpoint público)
az storage blob url \
--account-name $STORAGE_NAME \
--container-name $CONTAINER_NAME \
--name "index.html" \
--auth-mode login \
--output tsv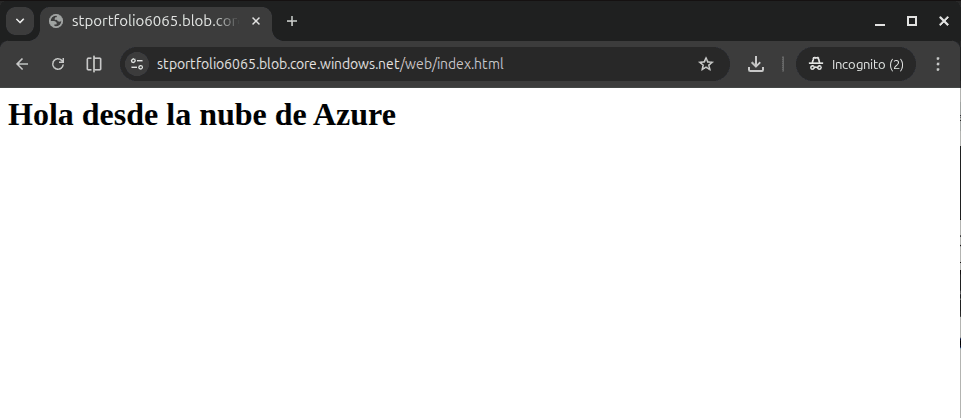
Eliminamos recursos creados
Una de las buenas practicas a la hora de aprender acerca de los servicios en la nube, es borrar todos los recursos que hemos creado para que no generen cargos innecesarios en nuestra cuenta. Para ello vamos a eliminar el grupo de recurso completo.
az group delete \
--name $RG_NAME \
--yes \
--no-wait
Conclusión
¡Felicidades! Has logrado desplegar una arquitectura robusta de almacenamiento utilizando infraestructura como código. Has pasado de entender la diferencia entre discos y objetos, a manejar identidades con Microsoft Entra ID y configurar políticas estrictas de Zero Trust. Este flujo de trabajo automatizado te ahorrará horas de clics manuales en el portal y es el primer paso para dominar pipelines de CI/CD.
¿Te topaste con algún error de permisos durante la propagación del RBAC o tienes dudas sobre cómo automatizar esto en GitHub Actions? ¡Déjame tus dudas en la sección de comentarios abajo y construyamos juntos en la nube!